

by John Ripple
Fizyr has optimized the three elements required for vision-guided robotics. Processing power optimized with an efficient algorithm. A unique data set of high-quality data built over many years. Intelligent deep-learning algorithms that have been trained through varied experience in commercial applications.
Vision Guided Robotics & Artificial Intelligence: An Explanation for the Non-Technical
The automation industry is experiencing an explosion of growth and technology capability. To explain complex technology, we use terms such as “artificial intelligence” to convey the idea that solutions are more capable and advanced than ever before. If you are an investor, business leader, or technology user who seeks to understand the technologies you are investing in, this article is for you. What follows is an explanation of vision-guided robotics and deep-learning algorithms.
That’s right, the article is titled “artificial intelligence” and yet by the end of the first paragraph, we have already switched to deep-learning algorithms! Industry hype works hard to convince you that “Artificial Intelligence = advanced and valuable” while “Deep Learning = nerdy and techy”. If you are a vision(ary) engineer designing your own solution, this article will be entertaining. If you are a business leader that wants to understand the basics, this is written just for you.
This article covers the following topics:
- Vision system types used in warehouse and distribution environments
- Basic building blocks for deep-learning systems
- Deep-learning vision systems for vision-guided industrial robots
Vision system types used in warehousing and distribution environments
There are three types or primary applications of vision systems used in warehousing and distribution environments. They are inspection and mapping, pick-and-place without deep-learning, and pick-and-place with deep-learning. All types of vision systems include three main elements: an input (camera), a processor (computer and program), and an output (robot). All types may use similar cameras and robots. The program is the difference.
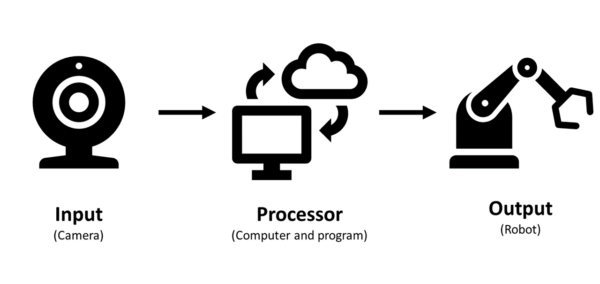
Inspection and Mapping
Vision systems for inspection are used in a variety of industrial robot applications, providing outputs of “pass/fail”, “present/not present”, or a measurement value. The result dictates the next step in a process. An example is using a vision system in a manufacturing cell to check for quantity present, color, or other pre-defined attributes (e.g., 3 red, 1 yellow, 2 blue). The results are communicated to an external processing system that takes a prescribed set of pre-determined actions.
Mapping systems are less frequently used but are similar to inspection systems, in that vision maps do not directly translate into machine action. An example is vision-navigation-based mobile robots (e.g., Seegrid). The map is created and stored in a database. The desired routes are pre-calculated. When the robot is driving through the system along pre-programmed paths, the vision system provides the ability to determine the robot X-Y position on a known map. An external routing algorithm provides instructions to the robot (continue forward, turn left, etc.) using the known map and the live camera feed.
Inspection and mapping systems can be very sophisticated, including the routing algorithms that guide the mobile robots, but they do not require deep learning or artificial intelligence.
Pick-and-Place, No Learning
Pick-and-place vision systems are deployed on most robotic cells installed today. A typical application is pick and place in manufacturing environments with limited variables. For example, pick up part A, B, or C from a defined zone and place them in a defined zone. These systems can differentiate between objects and the background based on simple features such as: shape, size, and color. The cameras direct the motion of the robot through closed-loop feedback, enabling the robots to operate very quickly and accurately, within their prescribed parameters.
These systems do not have a “learning loop” that enables the system to be smarter today than the day it was programmed. They are pre-programmed for a fixed set of objects and instructions. While these systems are “smart”, they do not add intelligence or learning over time.
By way of comparison, this would be like owning a self-driving automobile that could only drive on known roads and in weather and traffic conditions that had been pre-programmed. The car could speed up and slow down, change lanes, stop at the lights… but if a new road is built, the car would not be able to drive on it. Would it be awesome technology? For sure. Would it have its limitations? Yes.
Deep Learning (a.k.a. Artificial Intelligence)
The most sophisticated vision systems employ “deep learning”. These systems are often described with sensational terms such as “artificial intelligence”. Complicating things further, many non-learning systems are marketed as if they have intelligent (learning) capability, leading to confusion. Deep-learning systems are a type or subset of “artificial intelligence”.
Deep-learning engineers use a small set of objects as the learning base and teach the computer program (algorithm) to recognize a broad array of objects based on the characteristics of a small sample. For example, if you can recognize a few types of stop signs, you can apply that knowledge to recognize many types of stop signs.
The deep-learning program learns features that are independent of the objects, so that it can generalize over a wide spectrum of objects. For example, through such a program, robots can recognize the edge of an object no matter the exposure of the camera or the lighting conditions.
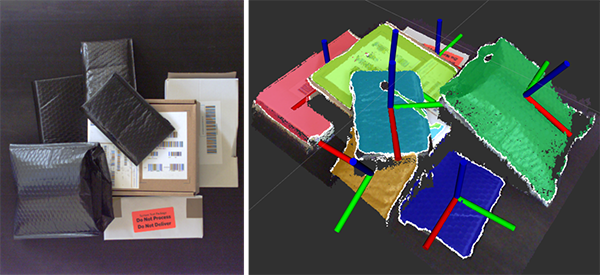
Deep-learning systems do not rely on a single variable, such as color, because something as simple as an exposure change or lighting would ruin the result. Color may be one of the variables, but additional more abstract variables are used for object recognition in the deep-learning program.
By way of comparison, these deep-learning systems used for robotic picking applications are like driving a Tesla in full autonomous mode. Park anywhere and navigate from A to B, using the best travel route in (most) any weather condition, on all road types.
Basic building blocks for deep-learning systems
Deep-learning principles used by industrial robots and Tesla self-driving cars are similar. Self-driving cars recognize different shapes, sizes, colors, and locations for stop signs. Once identified as a stop sign, the algorithm calculates a response based on external variables, such as location and direction of movement of other cars, pedestrians, road features, etc., and those calculations must be fast.
Vision-guided robots with deep-learning programs for industrial applications recognize various types of packaging, location, and other variables (e.g., partly buried under other packaging) and direct machine action based on those variables. Compared to self-driving cars, some of the variables for industrial robots are not as complex, but the underlying approach to learning and responding quickly is the same.
There are three requirements for deep-learning solutions: computer processing power, high-quality and varied data, and deep-learning algorithms. Each requirement is dependent on the other.
Computer Processing Power
Twenty years ago, the world’s largest supercomputer was capable of 12 Teraflops (12 Trillion Calculations per Second). That supercomputer used 850,000 watts of power, which is sufficient to power several dozen homes. Today, the Tesla Model S is equipped with 10 Teraflops of computing power!
While the ability to play graphics intensive video games in your Tesla gets the press, the real reason we need all the computing power is to run deep-learning algorithms that enable autonomous driving. Only 5 or 10 years ago, the processing power required to commercially develop and deploy deep-learning algorithms for use by everyday retailers and manufacturers did not exist.
Data… not just more of it, but more complex variations
Deep-learning algorithms become better as they encounter more complex and varied data. Improving the algorithm depends on the quality of the data, not just more of the same. New variations of data (objects) that are not similar to existing known objects enable algorithm improvements. The algorithm is trained to categorize new objects based on deeper-level variables.
In the case of Fizyr, when the algorithm fails to properly segment objects in the current system, the negative examples are used to re-train the model. That is what is meant when referring to continuous learning. Of course, the goal is to reduce the number of negative examples.
Deep-learning algorithms do not have a threshold where more data (better, more varied data) no longer leads to improving performance. This is why companies like Fizyr that have been deploying their deep-learning algorithms in commercial applications for several years, have a significant advantage over newer suppliers. More experience leads to better algorithms, which in turn leads to better system performance.
Deep-learning algorithms
The algorithm must be efficient to maximize the combination of available data and processing power. The algorithm outputs are instructions that can be executed by the machine (robot or car).
Deep-learning algorithms classify data in many levels or categories. The levels of identification are what make it “deep” learning. Using a sports analogy: what sport, type of ball, field conditions, direction of play, location and direction of movement of other players, ball movement, your desired action — score a goal! When in learning mode, the deep-learning algorithm calculates all the inputs and variables (a trillion calculations per second) and instructs you to kick the ball low and hard with your left foot, causing the ball to travel to the top right corner of the net. Score!
Processing power in concert with intelligent algorithms enable speed. Take a picture, transmit the data, classify, determine desired outcomes, and issue executable instructions – in a second or less. Fizyr algorithms provide over 100 grasp poses each second, with classification to handle objects differently, including quality controls to detect defects. Mind boggling performance that is only possible with intelligent algorithms and fast computers. Better data enables smarter algorithms. It is a virtuous cycle.
Fizyr has optimized the three elements required for vision-guided robotics. Processing power optimized with an efficient algorithm. A unique data set of high-quality data built over many years. Intelligent deep-learning algorithms that have been trained through varied experience in commercial applications.
Deep-learning vision systems for vision-guided industrial robots
Commercial applications using robots to pick, place, palletize, or de-palletize in a warehouse environment require three basic building blocks: cameras, software, and robots. The cameras and robots are the eyes and arms. The software is the brain.
The deep-learning algorithm takes in a flow of data from the cameras and provides instructions to the robots. The cameras and robots need to be suitable for the application, but do not provide the intelligence. All three components must work together to optimize system performance.
Camera Technology
Camera technology enables the flow of high-quality data. Cameras and post image processing provide a stream of data ready for the deep-learning algorithm to evaluate. While the camera technology is important, in many ways it is comparable to a computer or robot. Some cameras provide better quality images or are better suited for an application, but the camera itself is not what makes a vision-guided robot capable of deep learning. The camera supplies data but does not translate data into actionable commands.
Software
The software is the deep-learning algorithm – data in from cameras, process, results out to robots.
Robot and End Effector
The robot and end effector (a.k.a. gripper) also play a critical role in system performance. They must provide the level of reach, grip-strength, dexterity, and speed required for the application. The robot and end effector respond to commands from the deep-learning algorithm. Without the deep-learning algorithm, the robot would respond to pre-programmed, pre-configured commands.

by Benjamin Alt
With the robot software from ArtiMinds you don’t need expensive hardware or complicated code and the training of your employees is included. Program your robot easily via drag & drop, our ArtiMinds RPS software automatically generates native robot code. Force control, image processing and PLC communication – you can solve even the most demanding tasks with our software. Planning, programming, operation, analysis and optimization of your robot application – with just one software.
Optimizing Robot Programs with Deep Learning
Due to their flexibility, modern industrial robots have become core technology components of state-of-the-art production facilities in nearly every industry. Their large number of degrees of freedom and the availability of intuitive software tools for programming, integrating and monitoring them have made them particularly effective for high-mix, low-volume production as well as sensor-adaptive applications. Both contexts are challenging to address with traditional automation technology: Achieving the required degree of flexibility would require the expensive development of custom hardware. This flexibility is offered at much lower cost by industrial robots and their surrounding sensor and software ecosystem.
While industrial robots allow to commission, program, deploy, monitor and adapt flexible production cells much more quickly and economically than traditional automation, those savings are largely due to reduced requirements of custom hardware and high potential for standardization. Their inherent flexibility means that parts of the costs are now shifted to the programming and deployment stages of the robot cell lifecycle – where adaptive force control or vision-based robot skills are now realized in software. The ArtiMinds RPS allows robot programmers to quickly program robots to solve complex tasks by combining pre-parameterized robot skills, with dedicated skills for force- or vision-controlled sensor-adaptive tasks. Skill-based robot programming, particularly in conjunction with the data visualization and analysis tools provided by ArtiMinds LAR, significantly lowers the remaining overhead of programming sensor-adaptive tasks, or of adapting existing robot programs for high-mix, low-volume manufacturing.
With skill-based robot programming reducing the overhead of programming robots, the central remaining cost factor of advanced robotic automation is the adaptation of robot skill parameters during ramp-up and deployment. Advanced force-controlled robot skills such as search motions or moment-controlled insertion can be adapted via a set of parameters, which define central aspects of the underlying motion or force controllers.
Consider the task of placing sensitive THT electronics components onto a printed circuit board (PCB), where the positions of the connector holes and the length and orientation of the pins vary within certain bounds due to manufacturing tolerances. A skill-based robot program to perform this task typically consists of a force-controlled approach skill to establish contact with the PCB, followed by a force-controlled spiral or spike search to find the precise position of the hole, as well as a force-controlled insertion motion to avoid damage to the components during insertion. The respective velocities, accelerations, PID controller parameters, but also skill-specific parameters such as the maximum contact force or the size and orientation of the spiral search motion can be parameterized.
The robot program parameterization bottleneck
- Force-controlled robot skills require careful parameter tuning for performance and reliability.
- Parameter tuning by human programmers is cost-intensive and requires expertise.
While the default parameterizations often solve the task, they should generally be fine-tuned to the particular application during ramp-up. This typically amounts to finding the parameterization which minimizes cycle time while respecting quality requirements – a challenging multicriterial optimization problem which requires significant robot and domain expertise and a possibly lengthy trial-and-error period during ramp-up, driving up costs and increasing time to production.
Automatic parameter optimization with Shadow Program Inversion
To further increase the cost-effectiveness of skill-based robot programming, we propose Shadow Program Inversion (SPI), a data-driven solution to automatically self-optimize robot skill parameters using machine learning. In recent years, machine learning-based approaches have been used with increasing success to increase the level of autonomy of robots in the industrial and service domains. Most notably, methods leveraging Reinforcement Learning (RL) or Learning from Demonstration (LfD) have shown promising results, teaching robots to perform complex tasks by exploring the space of possible actions in the environment (RL) or learning from human teachers (LfD). Both approaches are limited in their applicability for industrial robot programming, however:
- Reinforcement Learning effectively automates the trial-and-error process by allowing the robot to repeatedly interact with the environment, which is not feasible at the ramp-up phase of a real-world production cell; RL in simulated environments requires highly accurate and compute-intensive simulators, and bridging the resulting gap between the simulation and reality is considered an unsolved problem.
- The application of Learning from Demonstration to robot skill parameter optimization is challenging for many industrial applications, where the speed and precision of modern industrial robots often far surpasses the capabilities of humans.
SPI, by contrast, has been designed to seamlessly integrate into the ramp-up and deployment process of robotic workcells. The core idea of SPI is to learn a model (called “Shadow Program”) of the robot program, which predicts the expected robot trajectory (poses of the tool center point (TCP), as well as forces and torques) given the program’s input parameters. We design this model to be differentiable: The model can provide an estimate of how small changes to the input parameters will affect the resulting robot trajectory. This property enables the optimization of the program’s inputs via gradient descent, an efficient method for solving the type of multicriterial optimization problems encountered in the fine-tuning of robot skill parameters.
Shadow Program Inversion: The workflow
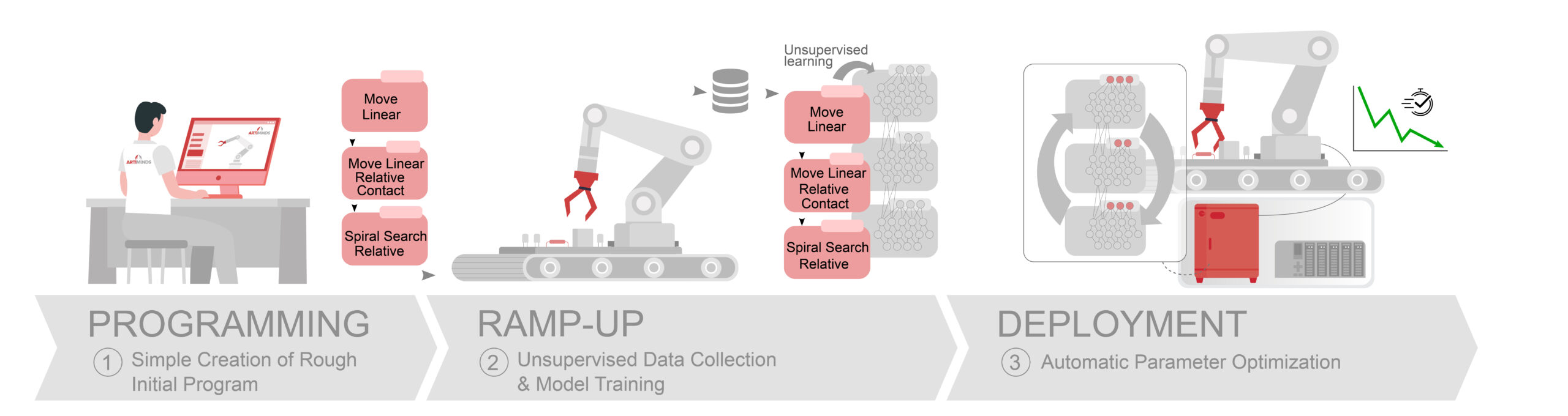
Figure 1 shows the complete workflow of parameter optimization with SPI.
- First, the robot programmer creates the robot program and provides a rough initial parameterization, typically based on CAD measurements and the default parameterizations provided by the RPS. For each parameter to be optimized – usually the parameters of particularly time-critical force-sensitive motions – she then defines the optimization domain, i.e. the range of permissible parameter values, to ensure safe operation of the workcell during the optimization process.
- SPI then autonomously collects data by repeatedly executing the program on the robot, sampling a new set of program parameters at each iteration and storing the resulting measured TCP positions, forces and moments. Once enough data has been collected, SPI trains the Shadow Program using this data.
- To obtain an optimal set of program parameters, the robot programmer must provide the objective function, which is to be optimized, usually a combination of cycle time minimization, some hard quality constraints reflecting the permissible tolerances and task- or workpiece-specific additional constraints, such as force or torque limits. SPI then computes the optimal parameterization via gradient descent over the shadow program with respect to the objective function and updates the robot program with the optimized parameters.
Properties and Advantages
SPI has several advantages which make it particularly applicable to real-world robot programming and deployment workflows:
- Decoupled learning and optimization. The core idea of SPI is to learn a model of the program, which then facilitates parameter optimization by being differentiable. This splits SPI into two distinct phases, a model learning phase and a parameter optimization phase. This split is advantageous for several reasons. First, it greatly improves the data efficiency of our approach, as the learning problem is considerably simplified, particularly compared to RL-based alternatives. Instead of having to learn what the program should do (i.e. learning an optimizer or an optimal policy in an RL manner), SPI only needs to learn what the program is doing (by simply observing repeated executions of the program with different parameters) – a much easier learning problem requiring much less data. The subsequent optimization step is pure computation – no learning required. Second, learning a model of the program instead of an optimizer can be done via unsupervised learning, requiring no human demonstrations or labelled training data. This enables the seamless integration of SPI into the ramp-up phase of the workcell lifecycle – data collection happens in the background while the workcell is undergoing regular preproduction testing.
- Optimization of arbitrary user goals. SPI allows the robot programmer to specify arbitrary user goals, provided they can be expressed as a differentiable function of the robot’s actions. This covers the most common objectives such as cycle time, path length or probability of failure, as well as most relevant process metrics or manufacturing constraints. Moreover, as a corollary of the split between learning and optimization, the user goals do not have to be known when training data is collected and the shadow model is trained, enabling the repeated optimization of parameters with respect to different, possibly changing objectives over the course of workcell deployment without requiring new data collection and training.
- Joint optimization for all skills in the program. Many challenging real-world tasks require several force-controlled skills to be executed in sequence. SPI jointly optimizes the parameters of all skills in the program, automatically respecting interdependencies between skills: For instance, the target pose of an approach motion will be optimized so that the succeeding search motion has the highest probability of succeeding. Alternative approaches require complex heuristics or human intervention to achieve this.
- Lifelong learning and re-optimization. The capability of SPI to optimize program parameters is not limited to the initial programming and deployment of the workcell. It also allows for the re-optimization of program parameters in the future, by simply collecting additional data during regular production, re-training the shadow model and recomputing the optimal parameterization. This is particularly relevant for high-mix, low-volume production, as the robot program, work pieces and possibly the workcell layout will change frequently. SPI has the potential of greatly reducing the overhead of manual reparameterization after every change, making small-batch, and flexible production much more economical.
Conclusion
In summary, SPI combines machine learning and gradient-based optimization to automate the optimization of robot parameters in a way that is particularly tailored to the pre-production stage of workcell deployment.
We have evaluated SPI on real-world electronics and mechanical assembly tasks involving complex sequences of search and insertion strategies.
We found that while RL-based alternatives or gradient-free optimization methods such as evolutionary algorithms were not applicable or ineffective in real robot cells, SPI effectively automated parameter optimization with resulting parameterizations which matched or outperformed human experts.
In addition, we demonstrated the flexibility of SPI by combining it with human demonstrations in a Virtual Reality (VR) environment and applied it in a household setting to move a glass into a sink.
We could show that one single demonstration was enough to not only optimize parameters, but to generate a good parameterization from scratch, demonstrating the utility of SPI beyond industrial robot programming.
We presented SPI at the 2021 IEEE International Conference on Robotics and Automation (ICRA), and patented the technology with the German patent office.
Current work is focused on reducing the data requirements of SPI even further, and on transferring SPI from the lab into real-world production settings.
If you are interested in the technology and seek an automated solution to optimize your robot programs, contact us at contact@artiminds.com